某篇开创了一个时代(算是吧)的文章。短短单栏十页。
Attention 机制、Transformer。
Transformer 前 NLP 领域占统治地位的是网络结构是各种 RNN 和 LSTM 等技术。Transformer 的过程相对来说简洁得多:只包含一对 Encoder-Decoder,其中的核心组成部分是一堆堆叠的 Attention 单元。
为啥叫“All you need”?因为这篇文章提出的网络结构是第一个仅用 Attention 机制,不用任何 RNN 或 CNN 相关结构搭建的网络。
[1706.03762] Attention Is All You Need(2017 年 6 月)
要干啥
Transformer 能干的事情挺多的,几乎一切序列相关的任务都能 handle。
论文中重点提到的是机器翻译任务。这里也以翻译为例。
Transformer
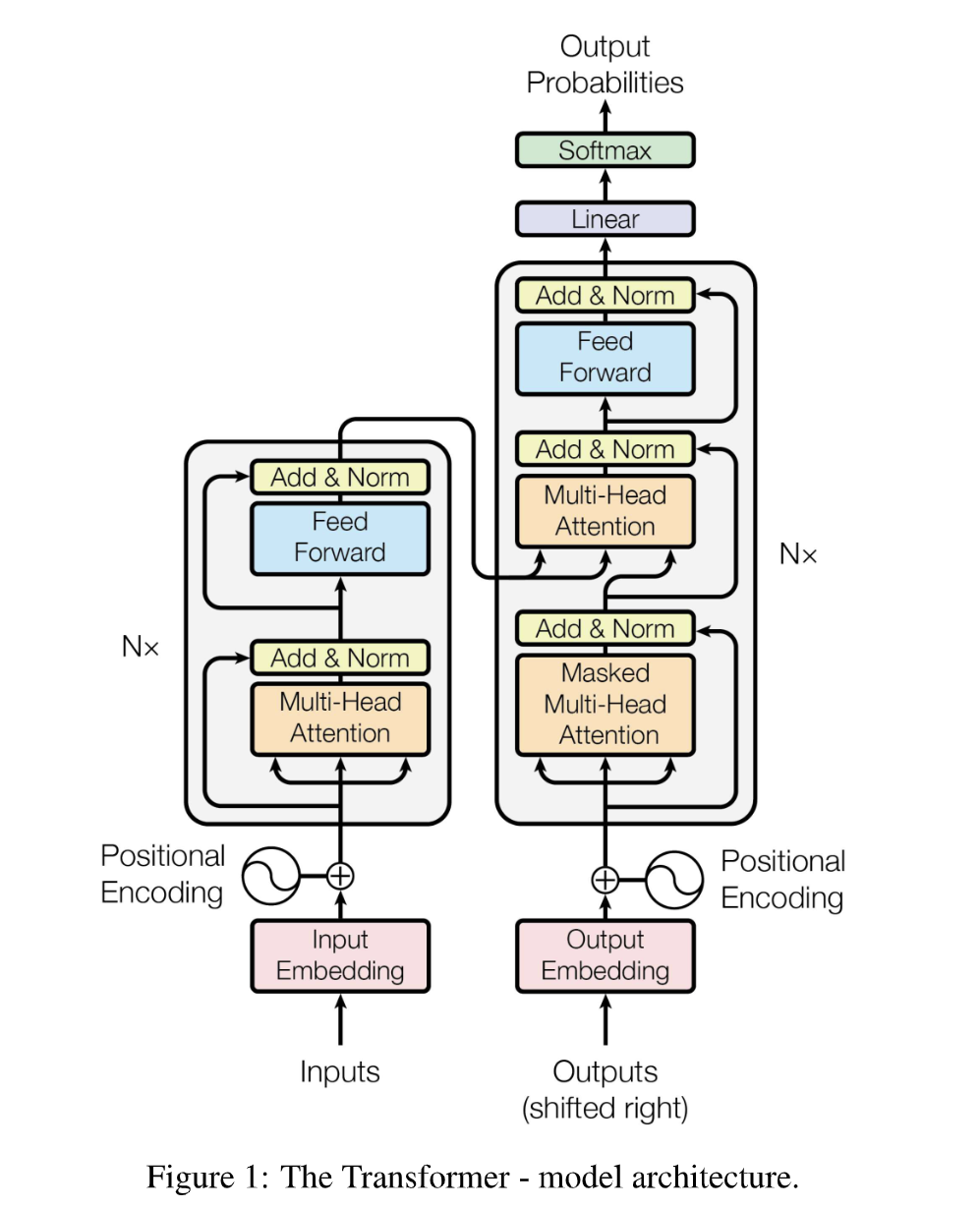
好经典的图啊。
Encoder 的作用是把输入的词向量
什么是自回归?Decoder 一个一个输出
的元素,每次根据 和 生成当前的 。
每个编码器分为
文中的 Attention 层都是多头的,一个 Multi-Head Attention 层由
Attention 层接受三个长为
观察上面的图可以发现,Encoder 用的 Attention 层和 Decoder 用的第一个 Attention 层分别用了三个一样的输入,称这种 Attention 层是 Self-Attention。Decoder 用的第二个 Attention 层采用了来自 Encoder 的输出作为
在下文中可以看到,Attention 单元内部的操作流程是固定的,没有可训练的参数。Attention 层中实际可训练的参数是上述的几个
Attention 机制
考虑这样一个问题:有一组
首先容易想到衡量两个向量
因为这些东西都会在神经网络的输出上进行,如果网络没炸的话可以认为
假设
然后把所有
现在假设有
为啥要除一个
?这是由于 (由于涉及到 个方差为 的元素相加)的方差会变为 , 较大时这个点积容易变得很大而整体跑到 Softmax 的两端去,从而除一个标准差进行归一化。
好草率的操作啊……但确实是那么回事……
那为啥叫“注意力”机制?
相当于是需要注意的地方, 对是所有地方以及它们实际存在的东西。
Why Attention?
文中居然专开一节讲了 Why!好感动好感动
……诶怎么感觉讲的全是废话
首先考虑为啥要有 Self-Attention 和 Cross-Attention。以翻译任务为例,Encoder 会把原来的句子编码成一串高维向量
再考虑为啥是 Attention 这个结构。一些原因:
- NLP 的任务往往是基于序列的,提取序列中长距离元素之间的关系是网络的一个关键能力。我们考虑网络中的数据流向,关注两个长距离元素第一次被关联到一起时经过的路径长度有多长,路径长度越短,经过的可训练参数就越少,这两个元的关联素便越容易被学习到。可以发现,RNN 连接长距离元素所需要经过的路径长度是
的;但 Attention 可以 连接序列中两个任意位置。 - 并行友善。
- 用 Self-Attention 搭起来的模型的可解释性更强。在研究 Transformer 能力的论文中经常能看到这种例子图:
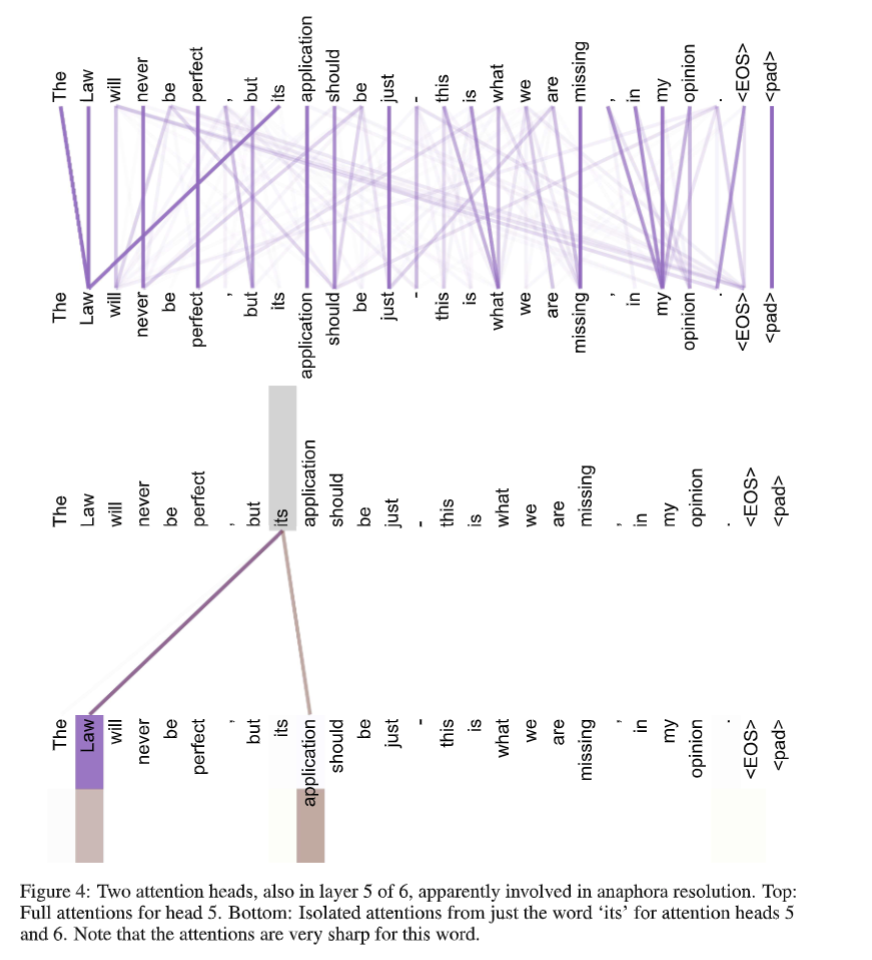
- 这种图是怎么来的?对一个长为
的句子,考察网络中某个特定 Self-Attention 头,它的 和 都是 的矩阵,对应于 个词的两种编码表示。把每个词的 和每个词的 点积,得到一个 的结果表示每个词在以每个词为询问时有多重要,这就可以画成上面的二分图了。这一般被称为 Attention 可视化,可以观察模型是怎么理解句子结构的。对 Cross-Attention 也可以画出类似的图。
为什么 Encoder 往 Decoder 传的数据被放到了中间层
的位置,而非 ? 这可以从上面的 Attention 可视化图入手。
共同控制了生成的 应该从之前的哪些 加权得到,而 才是最终 Decode 变成词的东西。以翻译任务为例, 的信息是关于句子结构的,是跨语言存在的,因此可以用于指导翻译后的句子应该长啥样,而 的信息是对每个语言 specified 的,把输入的中文的 丢到输出的英文的 里面显然会干扰生成。 事实上 Transformer 在别的领域的应用也遵循这个原则。有篇做图像风格迁移的论文(TODO)也是把图像结构信息作为
然后风格信息传 了 这么一看好像风格迁移任务和翻译任务挺像的……?
还有没有别的结构具有和 Attention 一样好甚至更好的性质?……不知道,我不想研究 NLP 啊……
本文地址: 笔记 – Attention Is All You Need
评论功能没修好,暂不开放