好家伙,比 3DGen 还早。还挺长,双栏 14 页。
提出了一种叫 VecSet 的 3D 表示方式。
[2301.11445] 3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models(2023 年 1 月)
居然有作者亲自讲解,太感动了……【SIGGRAPH 2023】3DShape2VecSet:面向神经场和生成扩散 – 哔哩哔哩
VecSet
3D 压缩表示希望做到的三点:体积小、压缩快、重建准确性高。根据可学习的内容(可操作空间)和恢复信息的方式可以把表示形式分为三种:纯显式表示、纯隐式表示、显隐混合表示。
纯显式表示的典型例子:搞一个网格,记录每个格点的各种信息,然后要查询一个点的时候直接在网格里插值。
纯隐式表示的典型例子就 NeRF,整个网络都是可学习的,然后输进去一个坐标就得到它的颜色等信息。
混合表示的典型例子就是我们所熟悉的 Triplane 啦。典型做法就是保存一些点的某种 Latent 特征,查询一个点的时候插值得到它的特征,然后过一个 Decoder。
截至目前都是废话。嗯。
表示一个 3D 形状时,需要存储它的哪些信息?可以考虑 Occupancy,输入一个点的时候输出它是否在这个形状内部。Occupancy 的显式表示就是 Voxel;隐式表示也有很多工作了。
大多数情况下,空间中绝大多数地方都是空的,因此可以考虑引入稀疏性而在稠密的地方多取点,以进一步压缩表示,提高表示效率。作者之前一篇论文引入了按稀疏性分布的不规则 grid,在它上面算特征然后插值。
这份工作干的事情是,不再采用 grid,直接算一组没有空间信息的特征,然后让模型学每个点应该从哪些特征上插值,即,可学习的插值。
即,之前的工作都是,查询一个点,根据某些规则找一组点插值;VecSet 干的是,查询一个点,模型自己找一组点插值。
这里的学习结构是 Cross Attention。为什么?
Cross Attention 会查
Cross Attention 的强大之处:可以把一种形式的输入转化为另一种形式的输出。具体地,可以把形如
的输入转化为形如 的输出。
分两步。第一步训一对 Encoder-Decoder,其能在 3D 形状和 VecSet 间互相转化。
第二步基于它们训 Diffusion 模型。
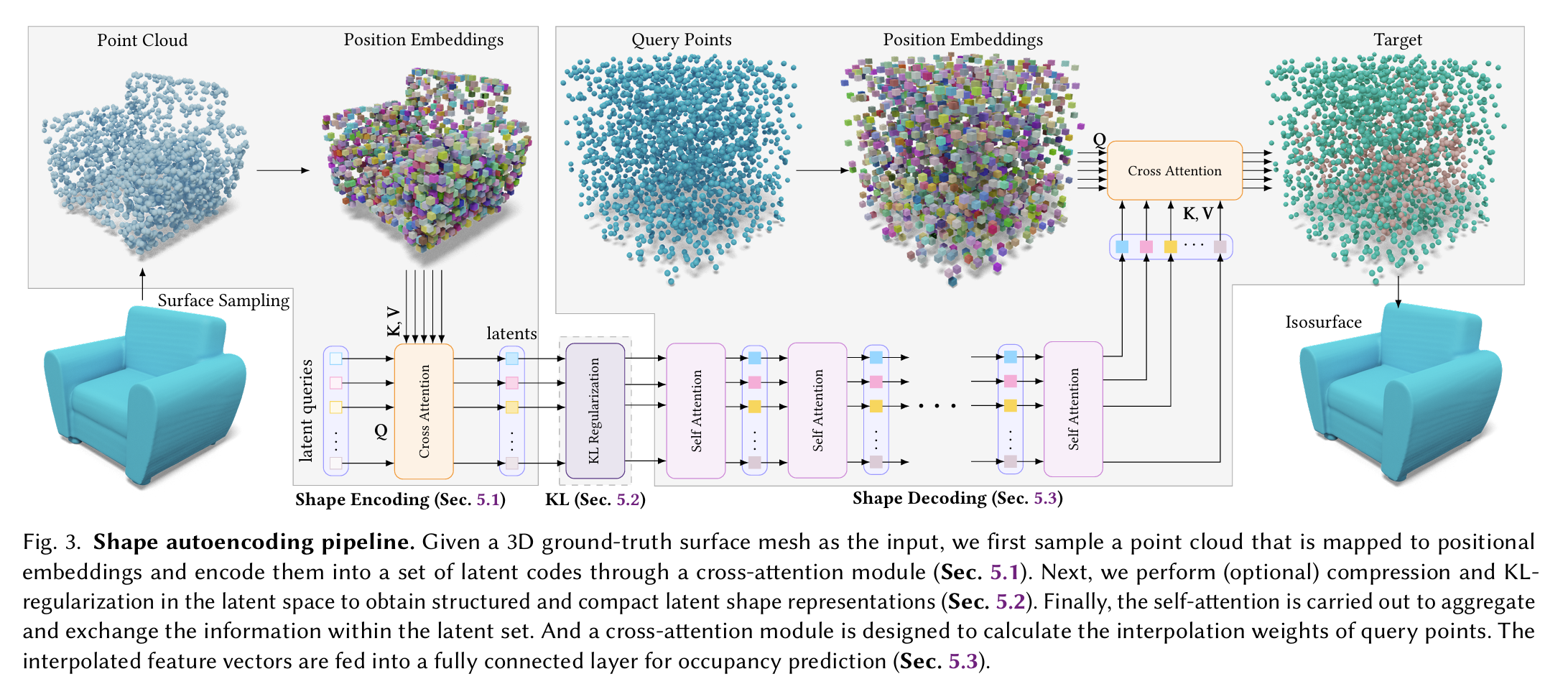
这个图很具有迷惑性!!怀疑作者根本不会画图!!
几个迷惑点:
- 图中出现了两个 Cross Diffusion,这两个 Cross Diffusion 的目的是完全不一样的!前者用于把点云信息编码成 VecSet,后者用于通过大量查询点从 VecSet 还原出点云信息。
- 中间那个 KL Regularization 的目的是压缩!类似 LDM 最开头那个 VAE。
其它
作者提到两种高分辨率 2D Diffusion 进路:基于低维 Latent 空间(如 LDM)和使用多个模型进行超分。作者实验得到的结论是(在 3D 场景下),Latent 空间的想法实践中更为优秀。
本文地址: 3DShape2VecSet – A 3D Shape Representation for Neural Fields and Generative Diffusion Models
评论功能没修好,暂不开放