啊……又回来了……熟悉的 DDPM 啊……
这篇文章的核心贡献在于:提出一种基于多轮 加噪 / 去噪 进行图像生成的方法框架。这种方法框架(Diffusion)在某种意义上独立于所采用的模型存在;模型所学习的是噪声——对某张带噪声图片来说,噪声最可能在哪,也即原图最可能长啥样子。
Diffusion 前最流行的图像生成方法是 GAN(标志性的工作如 StyleGAN),次一些的有 VAE(变分自编码器)、流方法、各种自回归模型等等,但它们训练效率往往极低,生成图片的质量也不很高(相对于 Diffusion 系列而言)。DDPM 作为最早的 Diffusion 方法之一并非很引人注目,但经过几轮论文周期升级而成的 DDIM、LDM / Stable Diffusion 很快展现出 Diffusion 系列方法的极高潜力,迅速席卷整个图像生成领域。
啥是 VAE?变分 自 编码器。
这里主要关注 DDPM 的数学方法及若干细节。
[2006.11239] Denoising Diffusion Probabilistic Models(2020 年 6 月)
看起来很厉害的博客 扩散模型之DDPM – 知乎
深入浅出且式子都很好理解的博客 生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼 – 科学空间|Scientific Spaces
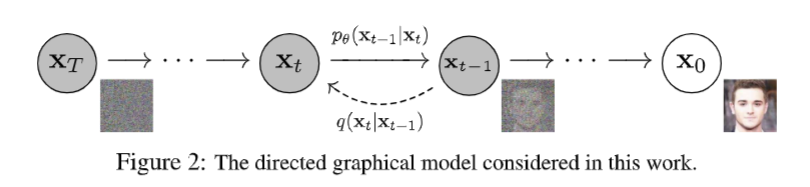
扩散过程
Diffusion 包含两个相反的过程:前向的扩散过程给一张图片加入
加噪过程中,第
上式含义:给定第
具体操作是
所有
为什么
要乘一个 ?因为希望 的方差一直是 ,这样最后得到的噪声图接近很简洁的 。
一个重要的事实是,由于 Gaussian 分布的可加性,
再记
然后
理想去噪过程
去噪过程中,第
等等!随机变量怎么可能“去掉”?毕竟我们也不知道它是多少啊!就算我们尝试用模型去预测加噪过程第
不管怎样,由于 Gaussian 分布的可加性,我们知道
来一个 Bayes:
为啥要再考虑
?因为 是由 生成的,没有单独的 ,或者说,当我们写出 时,其实就自带为 了。 或者说,这里讨论的是理想去噪过程,在仅知道一张噪声图
(而不知道原图可能有哪些)的情况下当然不可能理想地恢复原图。 模型到时候会在图片集上训练,尝试做到仅根据输入的
恢复原图。我们把这个过程记作模型去噪过程 ,以与理想去噪过程区分。 那为啥最后那项没有
?带上也行,但由 Markov 链的原因, 只和 相关所以多此一举。
(现在我还不知道要干啥……但可以把前面的东西代进来所以就代吧)
利用 Gaussian 分布的密度函数(省略
后面
为什么要化成这样?因为我们已经知道,
注意到方差是一个常数,这是自然的。均值则是一个关于
模型去噪过程
对
衡量两个分布的“接近程度”有 KL 散度,我们计算
KL 散度(Kullback-Leibler Divergence)是衡量两个分布之间差异的方法,广泛运用于机器学习等领域。它有一个不那么唬人的名字叫“相对熵”。
注意到这个式子是不对称的!!其中,
是真实分布, 是近似分布。 对两个 Gaussian 分布来说,KL 散度可以用以下式子计算:
好难推……ML 研究的数学爆算浓度这么高吗……
无论如何,上面
和 的 KL 散度就是直接代入上式的结果。
把这个作为优化目标就行啦。
但是但是!DDPM 发现这样效果不好,因此实际不是这样干的。之前得到一个这样的式子:
在已知
对
现在不让模型预测
再次地,不管前面那一坨常数,得到最终的优化目标:
真好。
所以还是要预测噪声,但噪声不是一个满足 Gaussian 分布的随机变量吗?
考虑
的意义:每次拿一张图片训练时对 加 步噪声之后得到 ,这 步噪声组合在一起是 。虽然分布 确实是一个 Gaussian 分布,但在已知 的情况下 所包含的信息量等价于 ,即,在已知 和原始图片集的情况下,预测噪声与预测加噪之前的图片等价。
总感觉论文作者的实际情况是先拍脑袋想出了这个优化目标,然后根据 KL 散度和之前 VAE 工作的范式证明了它的正确性……
毕竟其中有大量“舍弃常数”的操作,如果仅关注关键变量的流向的话,对
的 误差、对 的 误差和对原始 Gaussian 分布的 KL 散度这三个目标在直观上看是极为相似的。
回顾一下这串推导都在干啥,毕竟我们似乎只是从一堆显然的事实推出了另一些显然的事实:
- 首先已知
和 的话(理想情形)可以推出 ,对 的分布有一个描述; - 但图片生成的时候肯定不能知道
,因此希望模型基于 预测的 分布和理想情形的 分布越接近越好,这是我们的原始优化目标,但这个显然没法算; - 我们用爆算证明了这三个优化目标在忽略常数的情况下等价:
- (VAE 的观点)
和 的 KL 散度; - (基于图片的误差)
和 的 误差; - (基于噪声的误差)
和 的 误差。
- (VAE 的观点)
- 然后发现最后一个优化目标实践中最方便,就用它了,直观上看着也挺合理。
如何训练?如何采样?
得到了上面那个优化目标之后训练的过程就非常简洁了。
Step 1 取一张图片
Step 2 计算
Step 3 把
采样过程也顺水推舟地出来了。
Step 1 随机产生一个
Step 2 对
Diffusion 的常用网络结构是基于 Attention 层和 Residual 块搭建的 U-Net,同时引入对时间步的编码。
实际采样过程中取的
本文地址: 笔记 – Denoising Diffusion Probabilistic Models
评论功能没修好,暂不开放