ViT(Vision Transformer)。利用 Transformers,以 patch 为单位解决图像相关问题。
在此之前图像相关网络结构还是 CNN 居多吧。
[2010.11929] An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale(2020 年 10 月)
想法
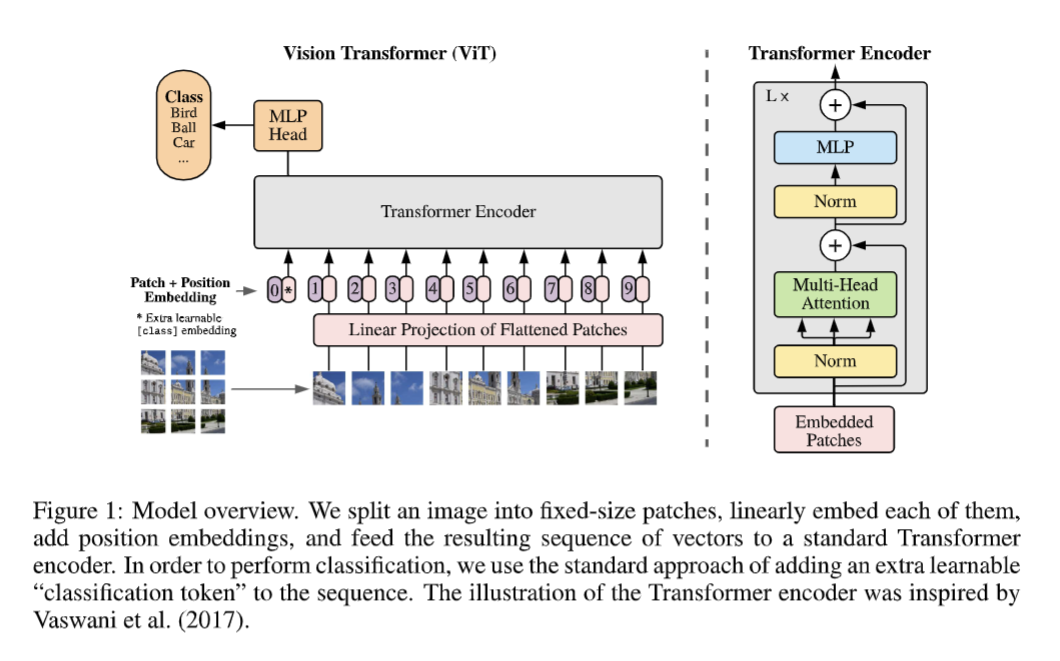
ViT 的基本想法是,以块(patch)为单位处理图片,把图片拆成一堆 patch 的序列,把这个 patch 序列输入 transformer。因此 ViT 中图片的一个 patch 等价于传统 transformer 中句子的一个词,这也是论文标题的由来。
每个 patch 进 encoder 之前要先位置编码,这个和处理文本的过程是相似的。在此之前,还有一步是过一个 MLP(线性投射层),类似词的编码。可以直接对 patch 这么干,也可以先过一层 CNN 然后在 CNN 的特征图上这么干。
为啥是 patch 而不是像素?
patch 才能提供一些特征信息。一个一个像素输入的话估计啥也看不出来。
ViT 也是有可解释性的。论文中给了一些例子的 attention map:

声明:
本文采用
BY-NC-SA
协议进行授权,如无注明均为原创,转载请注明转自
大仓库
本文地址: 笔记 – An Image is Worth 16×16 Words – Transformers for Image Recognition at Scale
本文地址: 笔记 – An Image is Worth 16×16 Words – Transformers for Image Recognition at Scale
评论功能没修好,暂不开放