EG3D 对三维场景的表示方式是 显式-隐式 混合的,这种表示方式之后被称为 Triplane。除此之外的主要贡献一个 3D GAN 的框架。
细节一堆。这里仅关注 Triplane 部分。
arxiv.org/pdf/2112.07945(2021 年 12 月)
这是啥?
EG3D 是一种 3D GAN,实现:输入单张 2D 图片,模型理解其三维内容,可以快速渲染出任意临近视角的观察结果。相比 NeRF 等纯隐式神经网络,EG3D 网络对三维物体的理解更加“显式”,可以提取出一些几何信息。
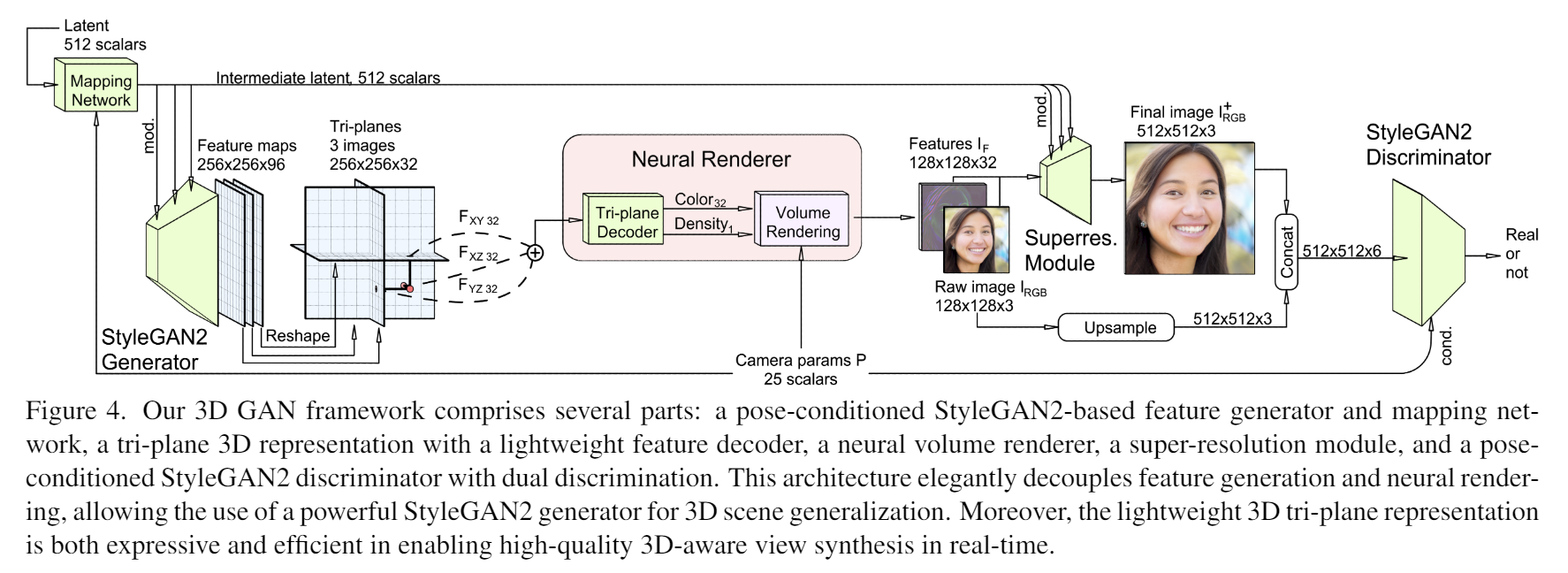
Triplane
既然是 GAN 就肯定有 Generator 和 Discriminator 两个部分。EG3D 的 Generator 包含两个阶段,其一是用一个基于 StyleGAN2 的网络(啥玩意)生成 3D 特征,其二是基于 3D 特征,带上相机信息利用神经渲染(具体而言就是体渲染)得到图片。
Triplane 就是 EG3D 的特征表示方式。其由三个互相正交的特征平面
在特征生成和体渲染中间插一个特征 Decoder,用于将特征解码为颜色+体密度用于体渲染。对每个待查询的空间点,在三个特征平面上插值得到这个点的三个特征(因为
为啥不直接用
的三维特征图?空间开销大。
那为啥不直接搞个巨大
的特征张量组,然后每个点以奇怪的方式映射上去?不清楚。表示能力差吧。
一般认为 NeRF 是典型的隐式空间表示;三维特征图是典型的显式空间表示。
声明:
本文采用
BY-NC-SA
协议进行授权,如无注明均为原创,转载请注明转自
大仓库
本文地址: 笔记 – Efficient Geometry-aware 3D Generative Adversarial Networks
本文地址: 笔记 – Efficient Geometry-aware 3D Generative Adversarial Networks
评论功能没修好,暂不开放